
Version Control System (VCS) is a more vital technical tool. It is mostly used among developer and IT specialist persons. It makes the developing phase more smooth. It helps to roll back when mistakes happen and collaborate with others developers.
The blog contents are organized according to the course "Introduction to Git and GitHub" which is one of the #google IT automation courses.
For building more conceptual knowledge about VCS's working principles, the basic Linux command 'diff' and 'patch' must be examined.
diff:
This command's name comes from 'difference'. It can compare two files line by line and give differences between them.
General Command of diff:
$ diff [option] file1 file2
This command gives only modified lines without line context. Sometimes it is difficult to understand the modification without line context.
So '-u' (unified) flag gives a more understandable output.
So command with -u flag:
$ diff -u file1 file2
Example of diff command:
Let's consider two files. One is 'diff1.txt'.

Now, the modified version of diff1.txt is 'diff2.txt'.

Now, if the command "diff -u diff1.txt diff2.txt" is executed on the cmd. We will get the difference between the previous one to the modified one.
Here, '-' (delete) indicates 'diff1.txt' and '+' (add) indicates 'diff2.txt'.
patch:
'patch' command is used to apply the diff changed on the original file.
"""The computer tool patch is a Unix program that updates text files according to instructions contained in a separate file, called a patch file. The patch file (also called a patch for short) is a text file that consists of a list of differences and is produced by running the related diff program with the original and updated file as arguments. Updating files with patch is often referred to as applying the patch or simply patching the files."""
Let's consider a real-life example where we need diff and patch commands together.
Finally, apply the patch file to the _original file.
Let's jump into git:
VCS keeps track of the changes we make to our files. we can know when the changes were made and who made them.
we can make edits to multiple files and treat that collection of edits as a single change, which is commonly known as a commit.
VCS provides reliability for a system. Suppose the code and configuration file of a running system is stored in VCS.
Now a new feature is required in that system, so the developer has modified the code and configuration and committed. But a bug was there, so for that reason, suddenly the system crashed and dependent people started to make a complaint for a while.
At that time, if the authority reverts to the old version of the code and configuration of the system, then the situation would be handled smartly and the developer would figure out the bug later.
git config:
The most basic use case of git config is to set email and username with the git repository.
$ git config --global user.email "user email"$ git config --global user.name "user name"
Here the command '--global' is an option that indicates the level of the configuration. It means that
"""Global level configuration is user-specific, meaning it is applied to an operating system user. Global configuration values are stored in a file that is located in a user's home directory.
~ /.gitconfig on Unix systems and C:\Users\\.gitconfig on windows"""We can check whether the 'user.email' and 'user.name' is set before or not.
$ git config --global user.email$ git config --global user.name
These two commands return the set value at the global level or git config -l can be used to get config values. There are other two-level --local, --system.
The main difference between --local and --global is that --local is set for the specific repository, but on contrary --global is set for all repositories for the specific user.
git init:
There are two ways to start working with a git repository. One: we can create one from scratch using the 'git init' command, or we can use git clone to make a copy of a repository that already exists somewhere else.
$ git init
This initializes an empty git repository in the current directory. we will find the .git directory in it. This .git directory maintains some of the important files to store the history of the working tree. The area out of the .git directory is a working tree, working tree tracks the current version of the project.
git status:
we can get some information about the current working tree and pending changes.
$ git status
git add:
$ git add [ filename ]
this command is used to track untracked files and add them to the current working tree. Then all the added files would in the staging area.
what is the staging area(index)!
A file maintained by git that contains all of the information about what files and changes are going to go into your next commit.

A file in git can be in three cycles of life such as untracked/unstaged or modified, staged/index and committed.
git commit:
all the staged files are taken to capture a Snapchat. The others unstaged and untracked files are ignored.
$ git diff
this command shows the difference between the older vision and the new version.
$ git diff
Remember that this will return only the difference of unstaged files/modified files.
But $ git diff --staged
It will return the difference of staged files.
Skipping the staging area:
$ git commit -a -m [short commit message]
Common mistake: someone can assume that this command is used for adding files (untracked and modified), and then committed them. But this is not correct.
This command is just a shortcut to stage any changes to only tracked files and commit them in one step.
$git log
It shows the git commit histories.
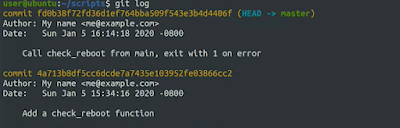
Here git uses the Head alias to represent the currently checked-out snapshot of the project.
$ git log -p
the -p flag (patch) is added to get more information such as where/ in which places changes were made.
Another command is available to see the details information for a specific commit.
$ git show [commit id]
One last topic: Deleting and renaming files
$ git rm [filename]
this command removes the file from the git directory, and remember that it must require committing the changes.
$ git rm --cached [filename]
this command removes the file from the git working-tree, but it will exist in your local directory as an untracked file. If someone wants to ignore the file in the future, then the .gitignore file can be useful.
$ git mv [old-filename] [new-filename]
this command renames the file name. It requires committing only.
But the interesting thing is that there is no scope for making stage anything.
So far in this blog, Introduction to git, Basic commands are covered. If anyone wants to know more and wants to become an advanced user. They can check out the next article.
You will find next Part 2, here: Git advance commands | undo changes | Rollback | Branches | Merging techniques - Part 2
Detached Head state of Git
Detached head means git "Head" is pointing to a commit without having any named entity such as a branch or tag. Git's routine garbage collection will delete those unnamed commits.
Precaution is to make a reference before moving away the 'head' pointer to the other branch. Reference could be branch or tag.
Precaution is to make a reference before moving away the 'head' pointer to the other branch. Reference could be branch or tag.
Last updated: 15.12.2024
0 comments:
Post a Comment